Optimizing Commitment Utilization
About Commitment Optimization
Commitment optimization is a feature of Compute Copilot for Karpenter, which allows it to effectively optimize utilization of pre-purchased commitments, such as Reserved Instances or Savings Plans, across an organization. In order to enable it on onboarded clusters, one of the NodePools for each cluster has to be marked as a template. This can be done by selecting the ‘Use as template’ option during or after creation of the NodePool.
Input data
nOps continuously monitors usage, Compute Savings Plans, Savings Plans and Reserved Instances across all configured accounts of an organization. We run hourly metadata ingest jobs and build a point-in-time representation of usage and commitment utilization in an organization. This allows us to find cases of commitment underutilization and overutilization. Underutilization happens when more commitments are purchased than used. Overutilization is the opposite case and is a potential candidate for divestment to Spot.
Additionally, for each configured cluster, we collect node metadata every five minutes. We collect information about node instance type, Availability Zone, platform and capacity type. This allows us to build a near real-time picture of usage that nOps manages in a cluster.
Optimization actions are performed at the intersection of sub-optimal commitments and usage we manage. For example, if we find out that there are unused RIs in us-east-1 but the clusters we manage are in us-west-2, we cannot do anything about that. Conversely, if the regions of the clusters and RIs match, we will try to divert usage in the cluster to cover the RIs.
Mechanism of action
Compute Copilot's main mechanism of action is creating and updating Karpenter NodePools. For example, if it determines that there are spare RIs in the m7i family equivalent to 10 vCPUs, it will find or create a NodePool that targets m7i instance with a vCPU limit of 10 and at a higher priority (weight) than other NodePools.
If, in the next hour, it finds out that m7i is now overutilized due to changing usage patterns elsewhere in the organization, Copilot will downadjust the NodePool and terminate an appropriate number of m7i instances. This will lead to Karpenter creating instances in another family and/or capacity type.
How does Compute Copilot distribute capacity between multiple configured clusters?
If you have more than 1 configured cluster, Copilot will try to intelligently allocate spare commitment capacity between them. Copilot will first "over-allocate" by creating NodePools in each cluster with a vCPU limit equal to the number of spare commitments. Afterwards, Copilot will monitor clusters to determine which clusters use up the allocated commitments. As soon as total utilization reaches the number of spare commitments, Copilot will readjust vCPU limits on all deployed NodePools to prohibit any further instance creation.
Existing Commitment Management
Using too much Spot can lead to under utilization of your purchase commitments like Savings Plans and Reserved Instances.
How does Compute Copilot allocate spare commitments without specific region or family requirements?
A Compute Savings Plan does not have specific requirements for a region, family, platform, or tenancy. In the case of an underutilized commitment, Compute Copilot will try to allocate equivalent vCPUs to any deployed NodePool with On-Demand only capacity type. Similarly, if it is conceptually possible to merge multiple commitments, Compute Copilot will try to consolidate them in one NodePool to avoid creating many NodePools.
To optimize utilization under a Compute Savings Plan, use the Use As Base feature. Simply mark a NodePool as a template in the NodePool Details by checking “Use As Base.” This signals the platform to prioritize On-Demand capacity, allowing nOps to automatically generate a new NodePool with identical specifications and integrate it seamlessly into your cluster. This feature ensures you avoid underutilization of your commitment.

If you don't select the Use As Base checkbox, nOps will automatically select a NodePool as a base.
The name will consist of an UUID prefixed with `nops-`.
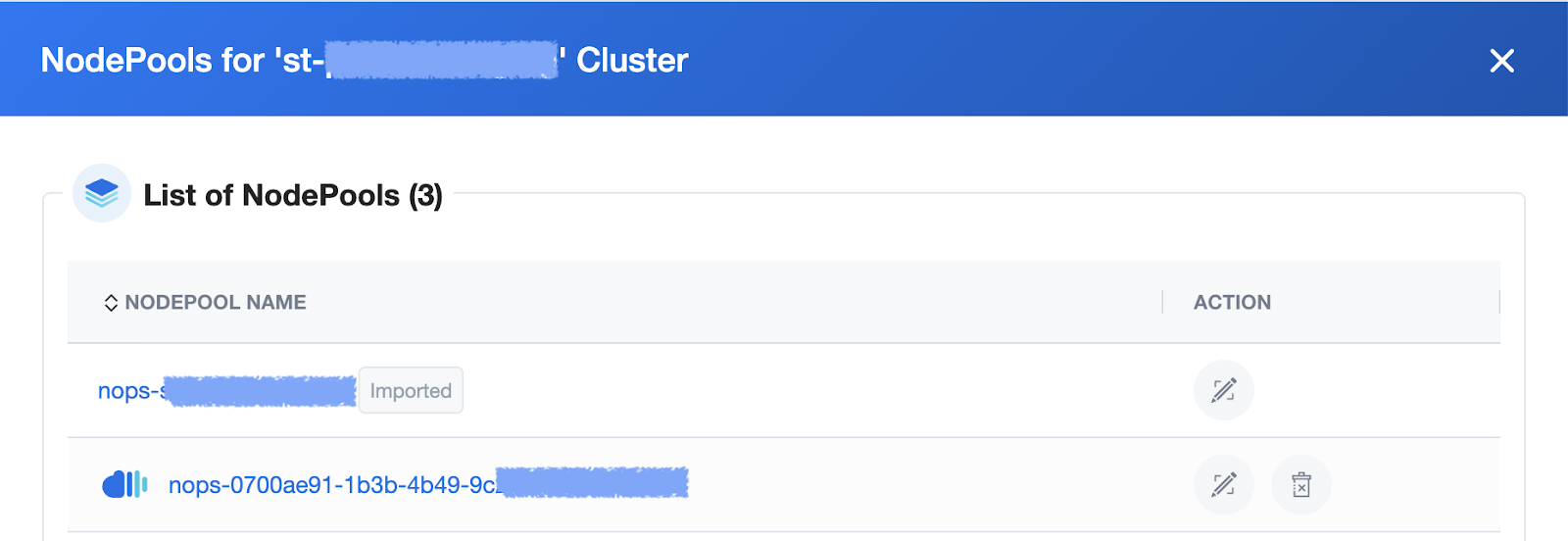
What is the configuration for the Auto-Created NodePool?
The Auto-Created NodePool will contain all the configuration specifications from the Base one with some small changes which are detailed below (weight, instance-families and VCPUs limit).
This will include the metadata but without the Kube generated fields, like resourceVersion or generation.
Weight
The weight of the NodePool will be set to the maximum weight of the existing NodePools + 5. This means that if the maximum current value is 90, the new weight will be 95. If the maximum value is 98 for example, the value will be capped at 100.
Instance-Families
The list of instance families will be contained from the Base NodePool filtered by specified limits.
VCPUs Limit
The VCPUs limit will be based on the calculated underutilization value and will be constantly adjusted to match the Commitment Plan.
Visibility Dashboard Utilization
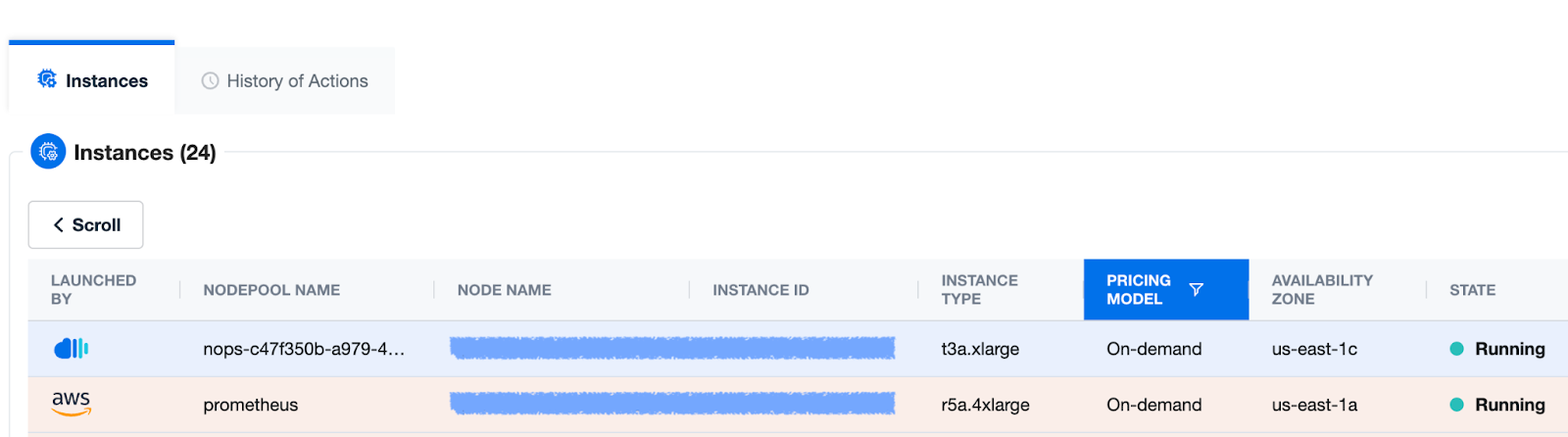
Here’s an example of how you can monitor your instances via the nOps Visibility Dashboard.
In the below picture you can find one On-Demand instance launched by the Auto-Created NodePool.